
原创
格式化两次datanode无法启动的解决办法
温馨提示:
本文最后更新于 2019年09月20日,已超过 2,507 天没有更新。若文章内的图片失效(无法正常加载),请留言反馈或直接联系我。
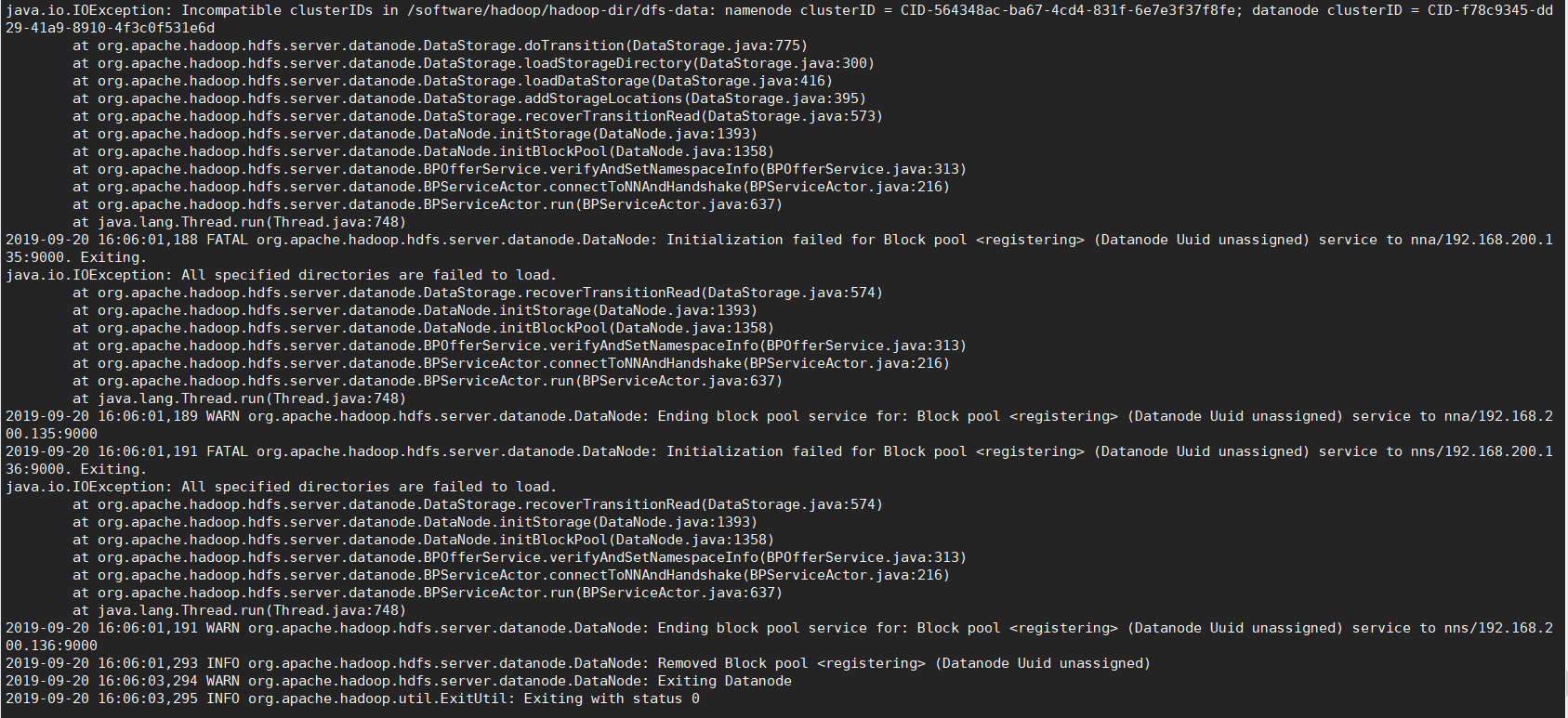
datanode无法启动报错,日志:
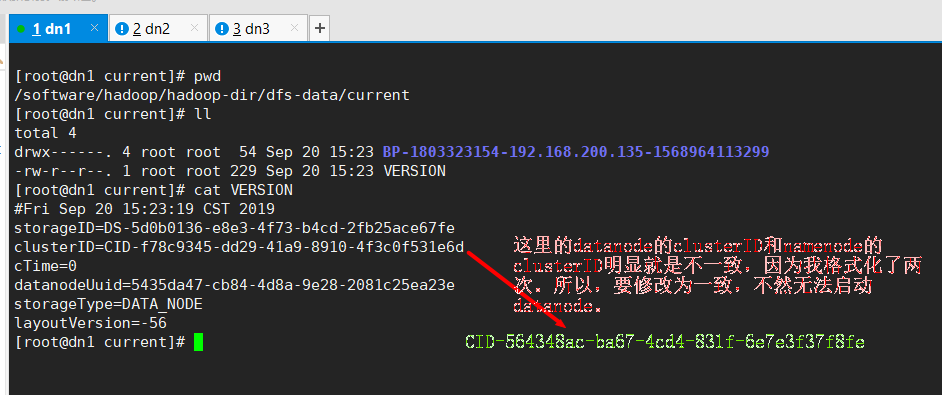
我看到了UUID,马上想到了clusterID,因为clusterID是UUID生成的,五台节点都要一致,namenode的clusterID和datanode的clusterID都要一致,都要是namenode的。
因为我配置错了,格式化了两次,所以会出现这样子的问题。
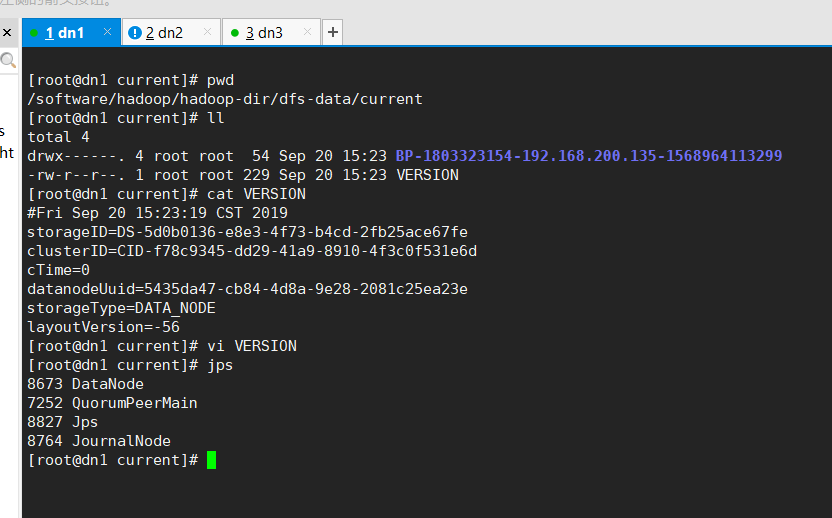
slaves之前也配置了三台datanode的主机名,所以,跟这个无关:
修改为namenode的clusterID的UUID序列号(两台namenode和三台datanode的clusterID要保持一致):
修改后,启动成功:
还有一种办法就是删除hadoop的data数据,重新格式化,我推荐修改一致。
- 本文标签: Hadoop
- 本文链接: http://www.lzhpo.com/article/20
- 版权声明: 本文由lzhpo原创发布,转载请遵循《署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)》许可协议授权
热门推荐









相关文章
关于我

会打篮球的程序猿
Talk is cheap, show me the code.

