
原创
安装Spark集群并测试
温馨提示:
本文最后更新于 2018年06月15日,已超过 2,933 天没有更新。若文章内的图片失效(无法正常加载),请留言反馈或直接联系我。
官方提供的四种安装方法
- Standalone Deploy Mode: simplest way to deploy Spark on a private cluster
- Apache Mesos
- Hadoop YARN
- Kubernetes
1.1下载Spark
去年我学Spark的时候,安装的独立模式的,不是分布式的,也是因为自己电脑资源不够用。
那时候还是2.3.2版本,现在就2.4.3了,由此可见,Spark更新还是比较快的。
1.2安装Spark(Standalone Deploy Mode)
在主节点master配置好
cp spark-env.sh.template spark-env.sh
vi spark-env.sh
# 添加配置
export JAVA_HOME=/home/java/jdk1.8.0_191 #Java
export SCALA_HOME=/home/scala/scala-2.12.8 #Scala
export SPARK_MASTER_IP=192.168.200.140 #主节点ip
export SPARK_MASTER_PORT=7077 #主节点端口
export SAPRK_WORKER_MEMORY=1g #每个worker进程能管理1g内存
vi slaves
# 添加配置
master
slave1
slave2
我的环境变量/etc/profile示例:
#JAVA_HOME
export JAVA_HOME=/home/java/jdk1.8.0_191
export PATH=${JAVA_HOME}/bin:${PATH}
export HADOOP_CLASSPATH=${JAVA_HOME}/lib/tools.jar
#SCALA_HOME
export SCALA_HOME=/home/scala/scala-2.12.8
export PATH=$PATH:$SCALA_HOME/bin
#SPARK_HOME
export SPARK_HOME=/home/spark/spark-2.4.3-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
之后再scp -r分发这些到slave1、slave2节点。
1.3启动Spark集群
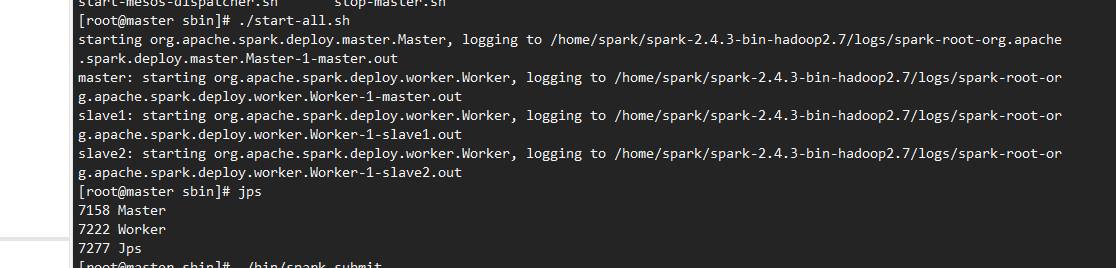
master节点:
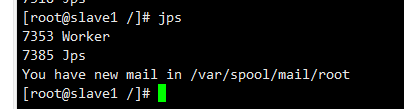
slave1节点:
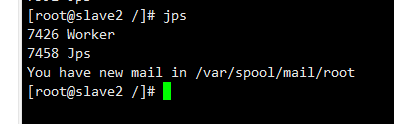
slave2节点:
1.4测试Spark集群
官方示例Jar包位置:
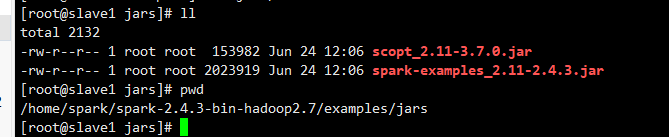
运行命令:
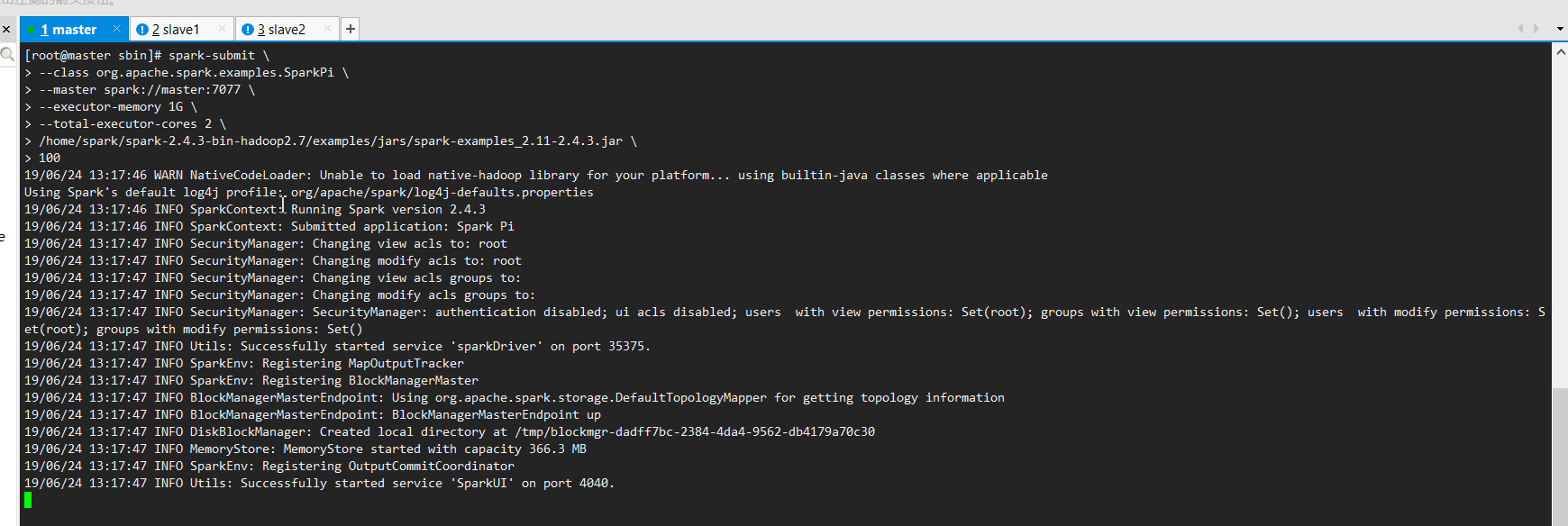
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://master:7077 \
--executor-memory 1G \
--total-executor-cores 2 \
/home/spark/spark-2.4.3-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.4.3.jar \
100
- spark-submit:提交任务。
- --class org.apache.spark.examples.SparkPi:运行的主类。
- --executor-memory 20G :控制 executor 的堆的大小。
- --total-executor-cores 2:分给executor多少核。
- /home/spark/spark-2.4.3-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.4.3.jar:官方文档示例Jar包。
spark-submit提交任务的,官方文档介绍的很详细:https://spark.apache.org/docs/latest/submitting-applications.html
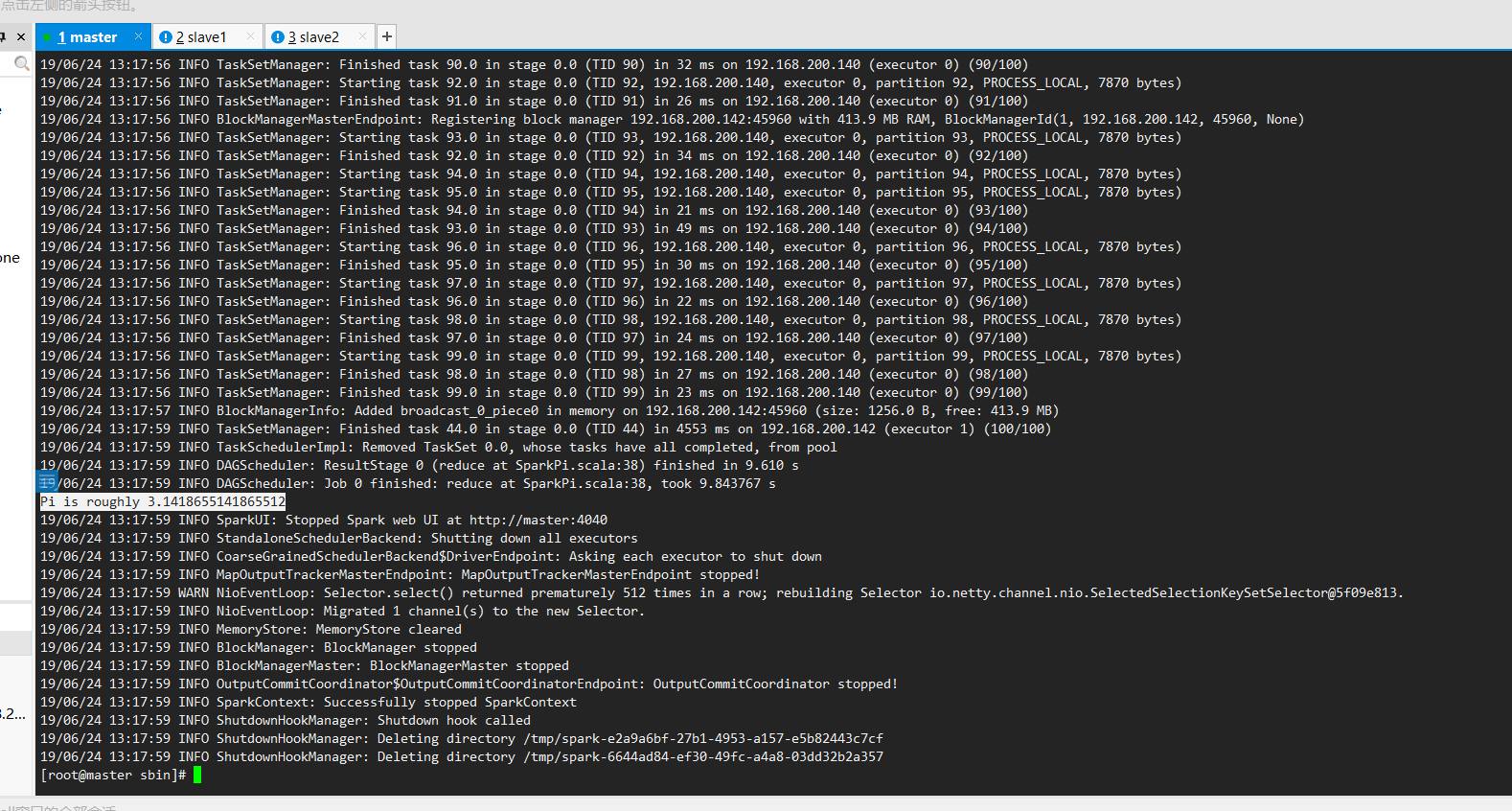
计算结果:
- 本文标签: Spark
- 本文链接: http://www.lzhpo.com/article/54
- 版权声明: 本文由lzhpo原创发布,转载请遵循《署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)》许可协议授权
热门推荐










相关文章
关于我

会打篮球的程序猿
Talk is cheap, show me the code.

