
原创
了解一下抖音推荐机制以及威尔逊得分排序算法
温馨提示:
本文最后更新于 2020年03月09日,已超过 2,337 天没有更新。若文章内的图片失效(无法正常加载),请留言反馈或直接联系我。
了解一下抖音推荐机制
抖音,相信大家都玩过,没玩过,那总听说过吧?你知道你为什么上不了热门吗?
其实,抖音的上热门的方法类似于威尔逊得分排序算法,但是远远又比威尔逊得分排序算法更复杂。
大概就是:
机器审核+人工双重审核。
当一个视频初期上传,平台会给你一个初始流量,如果初始流量之后,根据点赞率,评论率,转发率,进行判断:该视频是受欢迎还是不受欢迎,如果第一轮评判为受欢迎的,那么他会进行二次传播。
当第二次得到了最优反馈,那么就会给与推荐你更大的流量。
相反,在第一波或者第N波,反应不好,就不再推荐,没有了平台的推荐,你的视频想火的概率微乎其微,因为没有更多的流量能看见你。
你的视频火的第一步是被别人看见,第一步就把路给走死了,后续也只能依靠朋友星星点点的赞。
其实,不难看出这个抖音推荐机制算法背后思维逻辑:流量池,叠加推荐,热度加权及用户心理追求。
下面还是来了解一下威尔逊得分(Wilson Score)排序算法吧!
威尔逊得分(Wilson Score)排序算法
威尔逊得分(Wilson Score)排序算法:是对质量进行排序,评论中含有好评还有差评,综合考虑评论数与好评率,得分越高,质量越高。
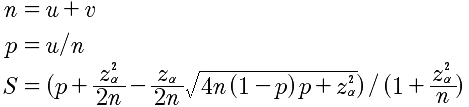
u表示正例数(好评),v表示负例数(差评),n表示实例总数(评论总数),p表示好评率,z是正态分布的分位数(参数),S表示最终的威尔逊得分。z一般取值2即可,即95%的置信度。
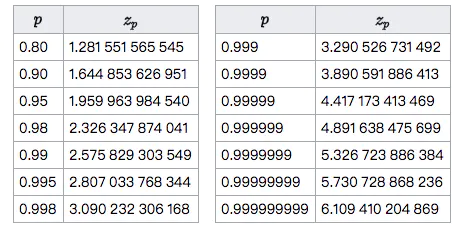
正太分布的分位数表:
算法性质:
- 性质:得分S的范围是[0,1),效果:已经归一化,适合排序
- 性质:当正例数u为0时,p为0,得分S为0;效果:没有好评,分数最低;
- 性质:当负例数v为0时,p为1,退化为1/(1 + z^2 / n),得分S永远小于1;效果:分数具有永久可比性;
- 性质:当p不变时,n越大,分子减少速度小于分母减少速度,得分S越多,反之亦然;效果:好评率p相同,实例总数n越多,得分S越多;
- 性质:当n趋于无穷大时,退化为p,得分S由p决定;效果:当评论总数n越多时,好评率p带给得分S的提升越明显;
- 性质:当分位数z越大时,总数n越重要,好评率p越不重要,反之亦然;效果:z越大,评论总数n越重要,区分度低;z越小,好评率p越重要;
威尔逊得分算法的分布图:
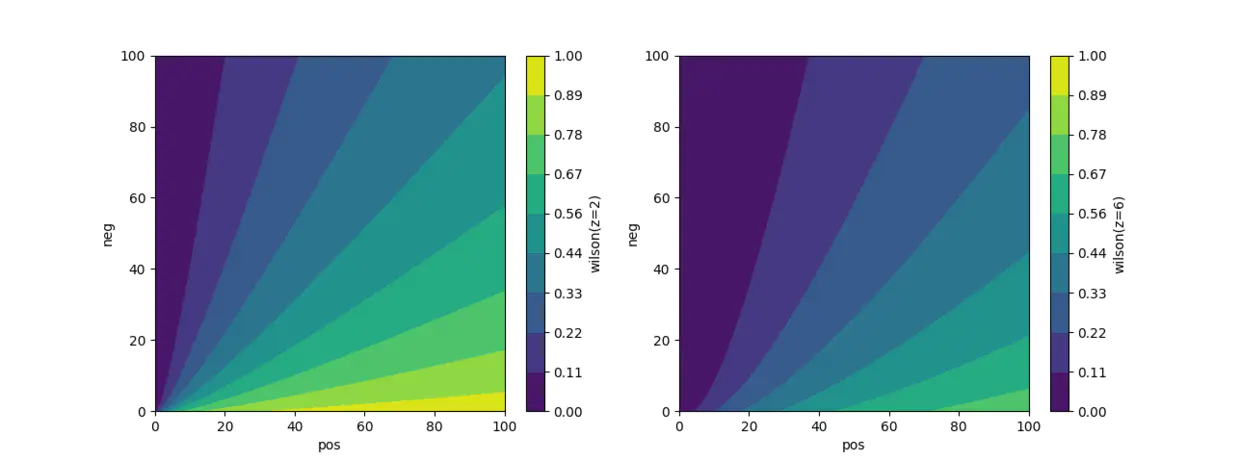
所以,zP一般是取值为2即可,即95%的置信度。
分别用Java、Python、Go实现
其实用什么语言实现都是一样的道理,编程在乎的是一种思想,在这里我罗列一下Java、Python、Go实现的代码,你就知道了。
Java实现
package com.lzhpo.wsdemo1.test1;
/**
* 威尔逊得分(Wilson Score)排序算法
*
* @author lzhpo
*/
public class WilsonScoreDemo1 {
/**
* 计算威尔逊得分
* <p>
* zP一般取值2即可,即95%的置信度。
* </p>
*
* @param u 好评数
* @param n 评论总数
* @param zP 正态分布的分位数
* @return s 威尔逊得分
*/
public static double wilsonScore(double u, double n, double zP) {
// 好评率
double p = u / n;
System.out.println("好评率为:" + p);
// 威尔逊得分
double s = (p + (Math.pow(zP, 2) / (2. * n)) - ((zP / (2. * n)) * Math.sqrt(4. * n * (1. - p) * p + Math.pow(zP, 2)))) / (1. + Math.pow(zP, 2) / n);
System.out.println("威尔逊得分为:" + s);
return s;
}
public static void main(String[] args) {
// 计算结果:0.46844027984510983
System.out.println(wilsonScore(500, 1000, 2));
}
}
Python实现
import numpy as np
def wilson_score(u, n, zP=2.):
"""
威尔逊得分(Wilson Score)排序算法 => 计算威尔逊得分
:param u: 好评数
:param n: 评论总数
:param zP: 正太分布的分位数(zP一般取值2即可,即95%的置信度)
:return: 威尔逊得分
"""
pos_rat = u * 1. / n * 1.
score = (pos_rat + (np.square(zP) / (2. * n))
- ((zP / (2. * n)) * np.sqrt(4. * n * (1. - pos_rat) * pos_rat + np.square(zP)))) / (1. + np.square(zP) / n)
return score
# 计算结果:0.46844027984510983
print(wilson_score(500, 1000, 2))
Go实现
package main
import (
"fmt"
"math"
)
// 威尔逊得分(Wilson Score)排序算法
func main() {
// 计算结果:0.46844027984510983
wilsonScore(500, 1000, 2)
}
// 计算威尔逊得分
// u:好评数 zP:正态分布的分位数(一般取值2即可,即95%的置信度) s:威尔逊得分
func wilsonScore(u float64, n float64, zP float64) float64 {
p := u / n
println()
fmt.Println("好评率为:", p)
s := (p + (math.Pow(zP, 2) / (2. * n)) - ((zP / (2. * n)) * math.Sqrt(4.*n*(1.-p)*p+math.Pow(zP, 2)))) / (1. + math.Pow(zP, 2)/n)
fmt.Println("威尔逊得分为:", s)
return s
}
- 本文标签: Java Golang Python
- 本文链接: http://www.lzhpo.com/article/115
- 版权声明: 本文由lzhpo原创发布,转载请遵循《署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)》许可协议授权
热门推荐








相关文章
关于我

会打篮球的程序猿
Talk is cheap, show me the code.

