
分库分表策略以及原理
什么是分库分表?
简单来说,就是将一个大型的数据库或表按照某种规则划分成若干个小型数据库或表,以提高系统的性能。
分库: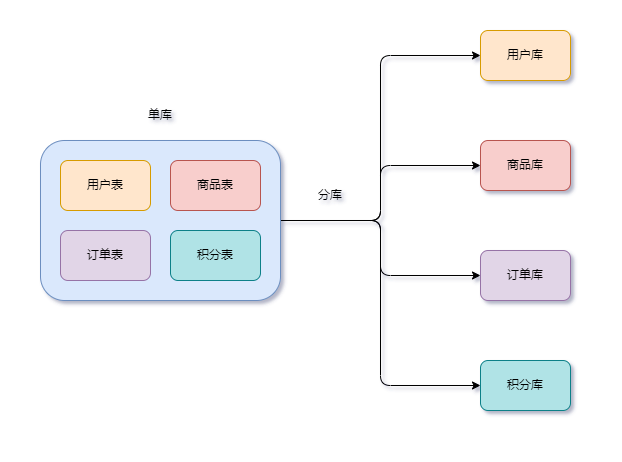
分表: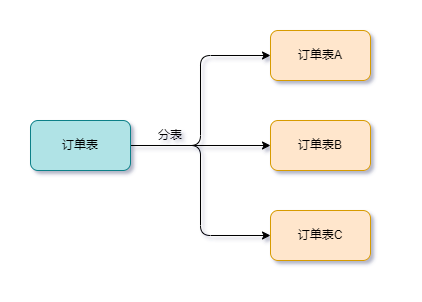
为什么需要分库分表?
主要原因就是为了应对数据量增大和访问压力增大的情况,因为当数据量和访问量增大时,单个数据库或表可能顶不住,此时可以通过分库分表,将压力分散到多个节点上,此时就可以提高系统的性能。
什么情况下才需要分库分表?
- 数据量大:单个数据库或表可能出现性能瓶颈,导致系统响应速度变慢,此时可以通过分库分表将请求或数据分散到多个节点上,以提高系统的并发处理能力。
- 访问量大:同上↑↑↑
- 存储空间:单个数据库或表存储空间不够时,需要考虑扩容,此时可以通过分库分表将数据分散到多个节点上,以提供更多的存储空间。
- 地域分布:可以按照地域规则将请求或数据分散到指定的机器上。
阿里巴巴Java开发手册中写到:
【推荐】单表行数超过 500 万行或者单表容量超过 2GB,才推荐进行分库分表。
说明:如果预计三年后的数据量根本达不到这个级别,请不要在创建表时就分库分表。
如何分库分表?
- 根据业务特点进行数据划分
例如:可以按照时间、地域、用户等维度进行数据拆分,使得同一类型的数据存放在同一个库或表中,避免数据交叉存储。 - 选取合适的分库分表策略
例如:垂直拆分和水平拆分。 - 设计合适的数据迁移方案
在不影响系统正常运行的条件下,将原有的数据迁移到新的库或表中。 - 减少对原有代码的修改
尽可能减少对原有代码的修改,不仅仅可以让原有稳定的业务正常运行,也可以减少工作量,毕竟修改了意味着需要重新测试,也需要承担出现Bug的风险。
有哪些分库分表策略?
简单画个大纲来方便理解:
水平拆分:
- 水平分库:将原本单库的表,变成多个库持有一张一模一样的表。
- 优点:可以支持更高的数据库并发,减少查询耗时。
- 缺点:提升了系统复杂度,因为需要设置规则如何路由到对应库的表,可能还会存在跨库的查询或者事务操作。
- 水平分表:将库中的一张表拆分成多张在此库中一模一样的表。
- 优点:解决了单张表数据量过大的问题。
- 缺点:多张表数据还是存在于单个库,压力还是给到单库。
垂直拆分:
- 垂直分库:将原本的单库,按照类型拆分成每个库负责专门的事情。
- 优点:将原本单库的压力分到了多个库。
- 缺点:没有解决单表数据量过大的问题。
- 垂直分表:将一张表按照字段拆分成多张表,表之间用ID进行关联。
- 优点:表结构更为简单,查询效率更高。
- 缺点:管理多张表增加了维护系统的成本以及需要联表查询增加了查询的复杂性。
分库分表有哪些分片策略?
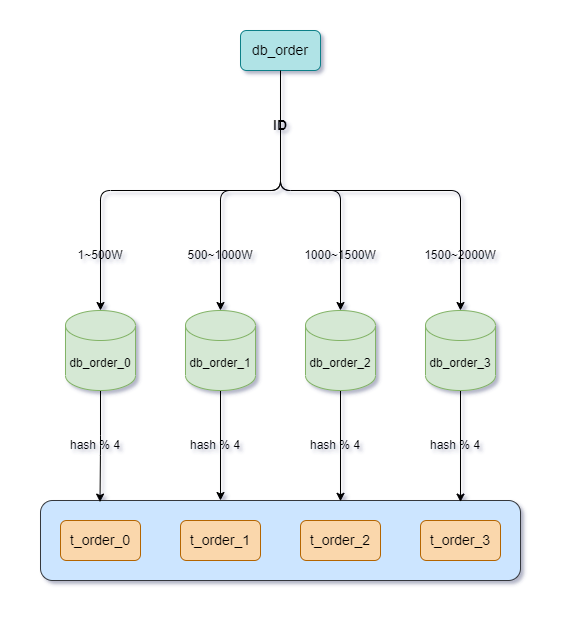
哈希取模分片:根据数据的哈希值进行取模分片,哈希取模值相同的数据存储在同一个分片中。优点是数据分布均匀,但是无法支持范围查询。
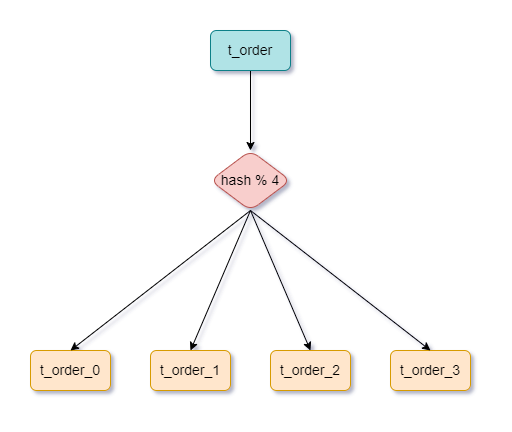
比如:
- hash=4,对4取模,值为0,落在
t_order_0。 - hash=1,对4取模,值为1,落在
t_order_1。 - hash=2,对4取模,值为2,落在
t_order_2。 - hash=3,对4取模,值为3,落在
t_order_3。
当然,不仅仅是hash取模,如果是ID的话也可以对ID进行取模。
- hash=4,对4取模,值为0,落在
范围分片:根据数据的某个范围值(如时间、ID等)进行分片,相邻范围值的数据存储在同一个分片中。优点是支持范围查询,但是无法保证数据均匀分布。
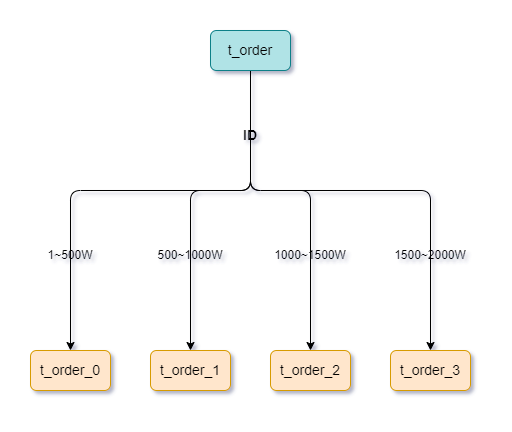
哈希+范围取模分片:就是结合哈希取模分片以及范围分片,结合哈希取模分片分散均匀的优点,将范围分片优化一下。
列表分片:根据一个预先定义好的列表将数据进行分片,每个分片包含列表中的一部分值。优点是可以手动控制数据分配,但是需要不断维护列表。
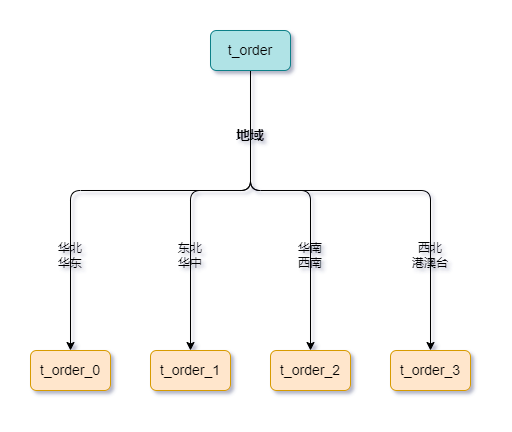
例如:每个表归划分几个地域列表,按照下单用户的地域进行划分(当然你也可以理解为是地域分片)。轮询分片:将数据均匀轮流分配到不同的分片中,避免了数据倾斜的问题,但是需要维护全局状态,可能会成为性能瓶颈。
随机分片:随机将数据分配到不同的分片中,可以避免数据倾斜,但是不适用于需要有序查询的场景。
读写分离实现原理?
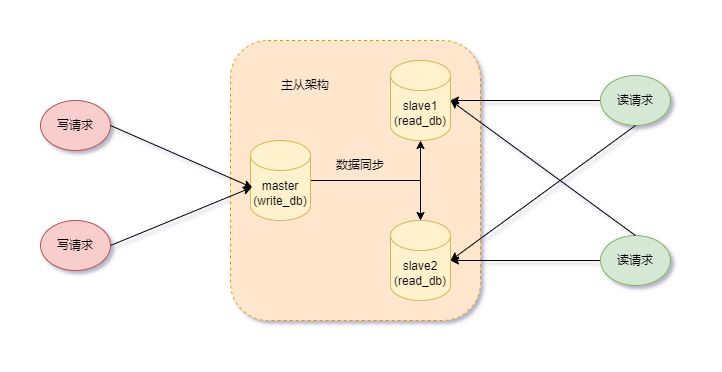
对于同一时刻有大量并发读操作和较少写操作类型的应用系统来说,可以充分利用MySQL主从架构,主库负责写请求(增删改),从库负责读请求(查询),能有效的避免因为数据更新导致的行锁,提高了系统查询性能。
主从架构的主库从库之间的数据同步以及延迟问题,sharding-jdbc无法解决。
分库分表会导致哪些问题?
- 分布式事务问题:在多个数据库进行事务操作,需要保证事务的一致性,否则会导致数据不一致。
- 跨库查询:跨库查询的性能和效率更低。
- 性能问题:数据被分散在不同节点上,跨节点查询会导致查询更慢,像执行一些
order by、group by、count等聚合函数,需要在多个节点将数据查询到,最后再汇总返回,分页也是类似的。 - 主键问题:不能再依赖数据库自增ID,一条数据需要有全局唯一的标识,可以使用雪花算法、UUID等。
- 分片策略问题:不恰当的分片策略以及没有维护一致的分片规则会导致数据不一致问题,所以需要确保每个分片的数据都是相互关联以及相互补充的。
- 系统复杂度问题:分片使得系统变得更加复杂,增加了维护的难度,并且当数据迁移以及备份的时候需要跨节点。
有哪些分库分表的中间件?
- ShardingSphere:由Apache Foundation孵化而来的开源项目,支持关系型数据库和非关系型数据库的分布式数据访问和分片,提供了完整的数据分片、读写分离、从库负载均衡、全局序列号生成等功能。
- MyCAT:基于MySQL协议开发的分布式数据库中间件,支持分片、读写分离、自动切换、服务发现等功能,可以用于大规模高并发的互联网应用场景。
- Vitess:由YouTube开源的分布式数据库中间件,支持MySQL协议,并提供了水平扩展、负载均衡、故障恢复等功能,适合大规模在线应用场景。
- TDDL:淘宝开源的分布式数据库中间件,支持MySQL和Oracle数据库,提供了水平分片、垂直拆分、读写分离、存储过程路由等功能,可用于海量数据的存储和查询。
- Atlas:由360开源的分布式数据库中间件,支持MySQL、PostgreSQL和MongoDB,提供了数据分片、读写分离、负载均衡等功能,可用于大规模高并发的互联网应用场景。
- 本文标签: Java 面试
- 本文链接: http://www.lzhpo.com/article/183
- 版权声明: 本文由lzhpo原创发布,转载请遵循《署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)》许可协议授权
热门推荐








相关文章
关于我


